

About Apache SparkLearn More
Apache Spark is an open-source unified analytics engine for analyzing large data sets in real-time. Not only does Spark feature easy-to-use APIs, it also comes with higher-level libraries to support machine learning, SQL queries, and data streaming. In a business landscape that depends on big data, Apache Spark is an invaluable tool.
Sort by:
Sorting
The newest
Most visited
Course time
Subtitle
Filtering
Courses


Subtitle

Linkedin Learning

Lynn Langit
Azure Spark Databricks Essential Training 2:52:18
English subtitles
12/05/2023



Subtitle

Linkedin Learning

Dan Sullivan
Introduction to Spark SQL and DataFrames 1:53:25
English subtitles
11/13/2023
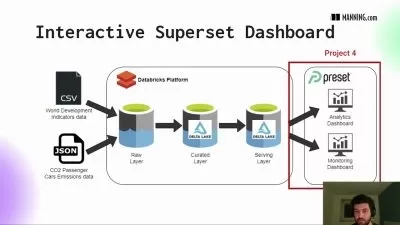
Subtitle
Subtitle




Subtitle

Udemy

Navdeep Kaur
Master Big Data - Apache Spark/Hadoop/Sqoop/Hive/Flume/Mongo 10:57:25
English subtitles
08/21/2023

Udemy

Aviral Bhardwaj
Databricks Certified Associate Developer for Apache Spark 3 4:15:26
08/20/2023
Books









Frequently asked questions about Apache Spark
Apache Spark is a framework designed for data processing. It was created for big data and is quick at performing processing tasks on very large data sets. With Apache Spark, you can distribute the same data processing task across many computers, either by only using Spark or using it in combination with other big data processing tools. Spark is an important tool in the world of big data, machine learning, and artificial intelligence, which require a lot of computing power to crunch massive amounts of data. Spark takes some of the burdens off of programmers by abstracting away a lot of the manual work involved in distributed computing and data processing. Programmers can interact with Spark using the Java, Python, Scala, and R programming languages. Spark also supports streaming data and SQL.
You will find Apache Spark developers wherever big data, machine learning, and artificial intelligence are used. You can find Spark being used for financial services to create recommendations for new financial products and more. It is also used to crunch data in investment banks to predict future stock trends. FinTech also uses it heavily. Developers in the health industry use Spark to analyze patient records with their past clinical data and determine future health risks. Manufacturers use Spark for large data set analysis. Programmers in the retail industry use it to marshall customers' data, create personalized services for them, and suggest related products at checkout. Machine learning engineers, data scientists, and big data developers also use Spark in the travel, e-commerce, media, and entertainment industries.
Apache Spark is a flexible framework for data processing, and there are some technologies it helps to know before you learn to use it. The first thing you need to know is how to interact with data stores, and there are a lot Spark can use. It also helps to know Hadoop, a popular distributed data infrastructure that is often used in conjunction with Spark for big data tasks. Knowing SQL allows you to interact with and retrieve data from databases if you plan on using them as a source for the data in Spark. Understanding the basics of a distributed database system like Hbase or Cassandra will also be useful. Being able to interact with Spark is important, requiring knowing a programming language that Spark understands. So to use Spark, you need to know either Java, Python, Scala, or the R programming language.