Spark 3 on Google Cloud Platform-Beginner to Advanced Level
No Latency
5:36:29
Description
Build Scalable Batch and Real Time Data Processing Pipelines with PySpark and Dataproc
What You'll Learn?
- Understand the fundamentals of Apache Spark3, including the architecture and components
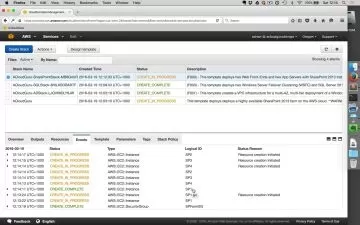
- Develop and Deploy PySpark Jobs to Dataproc on GCP including setting up a cluster and managing resources
- Gain practical experience in using Spark3 for advanced batch data processing , Machine learning and Real Time analytics
- Best practices for optimizing Spark3 performance on GCP including Autoscaling , fine tuning and integration with other GCP Components
Who is this for?
What You Need to Know?
More details
DescriptionAre you looking to dive into big data processing and analytics with Apache Spark and Google Cloud? This course is designed to help you master PySpark 3.3 and leverage its full potential to process large volumes of data in a distributed environment. You'll learn how to build efficient, scalable, and fault-tolerant data processing jobs by learn how to apply
Dataframe transformations with the Dataframe APIs ,
SparkSQL
Deployment of Spark Jobs as done in real world scenarios
Integrating spark jobs with other components on GCP
Implementing real time machine learning use-cases by building a product recommendation system.
This course is intended for data engineers, data analysts, data scientists, and anyone interested in big data processing with Apache Spark and Google Cloud. It is also suitable for students and professionals who want to enhance their skills in big data processing and analytics using PySpark and Google Cloud technologies.
Why take this course?
In this course, you'll gain hands-on experience in designing, building, and deploying big data processing pipelines using PySpark on Google Cloud. You'll learn how to process large data sets in parallel in the most practical way without having to install or run anything on your local computer .
By the end of this course, you'll have the skills and confidence to tackle real-world big data processing problems and deliver high-quality solutions using PySpark and other Google Cloud technologies.
Whether you're a data engineer, data analyst, or aspiring data scientist, this comprehensive course will equip you with the skills and knowledge to process massive amounts of data using PySpark and Google Cloud.
Plus, with a final section dedicated to interview questions and tips, you'll be well-prepared to ace your next data engineering or big data interview.
Who this course is for:
- Data engineers or data analysts who want to learn how to use Spark3 on the Google Cloud Platform (GCP) for large-scale data processing and analysis
- Software developers who want to integrate Spark3 into their applications or workflows running on GCP
- Data scientists who want to leverage Spark3's machine learning capabilities on GCP for building and deploying predictive models
- Anyone who wants to get started with their cloud journey with Spark 3
Are you looking to dive into big data processing and analytics with Apache Spark and Google Cloud? This course is designed to help you master PySpark 3.3 and leverage its full potential to process large volumes of data in a distributed environment. You'll learn how to build efficient, scalable, and fault-tolerant data processing jobs by learn how to apply
Dataframe transformations with the Dataframe APIs ,
SparkSQL
Deployment of Spark Jobs as done in real world scenarios
Integrating spark jobs with other components on GCP
Implementing real time machine learning use-cases by building a product recommendation system.
This course is intended for data engineers, data analysts, data scientists, and anyone interested in big data processing with Apache Spark and Google Cloud. It is also suitable for students and professionals who want to enhance their skills in big data processing and analytics using PySpark and Google Cloud technologies.
Why take this course?
In this course, you'll gain hands-on experience in designing, building, and deploying big data processing pipelines using PySpark on Google Cloud. You'll learn how to process large data sets in parallel in the most practical way without having to install or run anything on your local computer .
By the end of this course, you'll have the skills and confidence to tackle real-world big data processing problems and deliver high-quality solutions using PySpark and other Google Cloud technologies.
Whether you're a data engineer, data analyst, or aspiring data scientist, this comprehensive course will equip you with the skills and knowledge to process massive amounts of data using PySpark and Google Cloud.
Plus, with a final section dedicated to interview questions and tips, you'll be well-prepared to ace your next data engineering or big data interview.
Who this course is for:
- Data engineers or data analysts who want to learn how to use Spark3 on the Google Cloud Platform (GCP) for large-scale data processing and analysis
- Software developers who want to integrate Spark3 into their applications or workflows running on GCP
- Data scientists who want to leverage Spark3's machine learning capabilities on GCP for building and deploying predictive models
- Anyone who wants to get started with their cloud journey with Spark 3
User Reviews
Rating

No Latency
Instructor's Courses
Udemy
View courses Udemy- language english
- Training sessions 71
- duration 5:36:29
- Release Date 2023/06/23