Apache Spark and Scala
Insculpt Technologies
7:40:00
Description
A complete Guide for Processing Big Data with Spark
What You'll Learn?
- Understand the limitations of Hadoop mapreduce and how Spark overcomes these limitations
- Gain expertise in Scala programming language and its characteristics
- Able to work with RDDs' and create applications in Spark
- A thorough understanding about Spark SQL by using SQL queries in Spark
Who is this for?
More details
DescriptionThis course on Apache Spark and Scala aims at providing an advanced expertise in big data Hadoop ecosystem. This course will provide a standard skillset which helps one become a specialist on the top of Big data Hadoop developer.Â
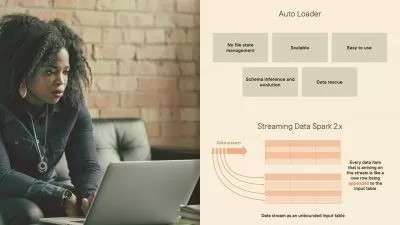
The course starts with a detailed description on limitations of mapreduce and how Spark can help overcome them. Further it covers a deeper dive into the Scala programming language.
Moving on it covers Spark as a standalone cluster and an understanding of Resiliient Distributed Datasets.
The course also covers concepts of Spark SQL using SQL queries through SQL context and Hive Queries through Hive context.
This course certainly provides material required for building a career path from Big data Hadoop developer to BIg data Hadoop architect.
Who this course is for:
- Students who aspire to gain a deep understanding of Apache Spark
- Professionals looking for a career in real time big data analytics
- Big Data and Hadoop Developers who want to analyze data faster
This course on Apache Spark and Scala aims at providing an advanced expertise in big data Hadoop ecosystem. This course will provide a standard skillset which helps one become a specialist on the top of Big data Hadoop developer.Â
The course starts with a detailed description on limitations of mapreduce and how Spark can help overcome them. Further it covers a deeper dive into the Scala programming language.
Moving on it covers Spark as a standalone cluster and an understanding of Resiliient Distributed Datasets.
The course also covers concepts of Spark SQL using SQL queries through SQL context and Hive Queries through Hive context.
This course certainly provides material required for building a career path from Big data Hadoop developer to BIg data Hadoop architect.
Who this course is for:
- Students who aspire to gain a deep understanding of Apache Spark
- Professionals looking for a career in real time big data analytics
- Big Data and Hadoop Developers who want to analyze data faster
User Reviews
Rating

Insculpt Technologies
Instructor's Courses
Udemy
View courses Udemy- language english
- Training sessions 66
- duration 7:40:00
- English subtitles has
- Release Date 2023/03/29